超轻量字符缓冲区库
在写yasf项目的过程中遇到这样的需求:为了构造SQL语句,我必须将若干个字符串拼接起来。一个凑合的办法是,定义一个足够大的静态缓冲区,然后使用诸如sprintf这样的库函数来构造字符串。但是事实上,构造出来的字符串的总长度是没有上限的。因此,若使用固定长度的缓冲区则会带来缓冲区溢出的隐患(C语言最著名的缺陷之一)。
大部分现代的语言的字符串功能都远强于C,字符串拼接更是非常基本的功能。选择C作为开发语言,那就不得不重复造轮子。我总抱着自己能造出更好的轮子的虚幻的指望。经过若干次试验,我得到了一种比较满意的实现方式。于是我把它从yasf项目中抽了出来,做成一个独立的模块,放在GitHub上,命名为ulbuf(__u__ltra __l__ightweight __buf__fer)。
整个实现的代码不足百行,功能也是少之又少。我发现,只有这样才能保证最大的灵活性。
整个库的特点:
简单
API非常简单,共4个函数。其中,2个用于缓冲区的创建和销毁,1个是为了便于使用而提供的便捷函数。因此,最关键的函数只有1个。
API的参数和返回值的形式是经过仔细设计的。
灵活
在C语言中,用户常常通过增/减指针来表示向字符串中增添/删除字符。只要预留了空间,ulbuf仍允许他们这样做。
在最初的实现中,ulbuf还保存了“缓冲区中已含有的字节数”这一个信息。并且只能向缓冲区中追加内容。对于yasf项目而言,已经足够。
现在的实现中,ulbuf只负责管理缓冲区的容量(最多能容纳的字节数),不储存已含有的字节数信息。既能简化实现,又能保证使用的灵活性。这可能是体现“少即是多”的一个例子。
鲁棒
当用户提示ulbuf需要向缓冲区中写入n个字符时,ulbuf会在第n+1个字符的位置写入字符'\0'。因此,缓冲区的内容永远是合法的C字符串。这样,使用C标准库操作缓冲区永远不会发生内存越界的错误。
协调
ulbuf创建的缓冲区是char *类型,可以把它当作正常的字符串,提供给诸如strlen、strchr这类标准库函数。
只要预留了空间,那么也可以把缓冲区作为输出参数,提供给诸如strcpy、sprintf这类函数使用也是完全没有问题的。这类函数会在第n+1个字符的位置添上一个字符'\0',仅仅是把ulbuf已经写入的'\0'覆写了一次,而没有发生内存越界访问。
高效
在我的平台上测试重复追加字符串的操作,ulbuf的运行速度略快于C++ STL的string类。
因为STL通常是仔细编写的、深度优化的运行库,可见ulbuf的运行效率是很高的。(欲知具体情况,可以编译并运行代码仓库中的example.cc程序。)
YASF的进度
yasf是我正在写的一个SQLite的图形前端。目前写好了大体的图形界面。能够读取SQLite数据库(而不能编辑)。
以下为未成品的截图。图中的对话框用于创建新的索引(仅仅是界面)。
扑克中的概率论问题
前天下午打牌,触景生情想起了一个概率论的问题:3个人打一副扑克(A23456789 10 JQK各4张+大小王=54张牌),随机发牌,每人拿18张。设随机变量X表示三个手中的炸弹(指4张点数相同的牌)的总数,求X的分布律。
这样的问题理论上应该可以使用古典概型来求解。但是我想了一会之后就放弃了。为了对这个问题有一个大概的了解,我写了一段程序模拟洗牌和发牌的过程并且统计其中的炸弹个数。
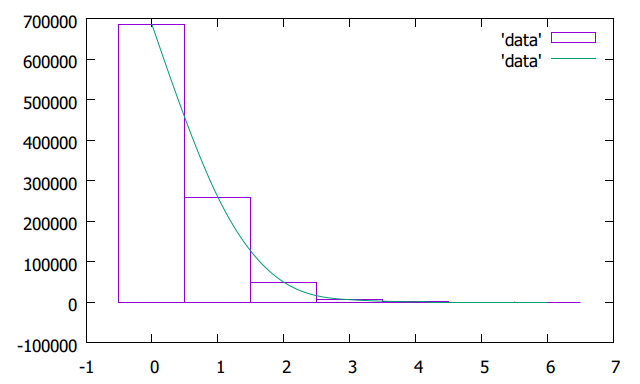
从程序的输出中我得到了一个有趣的结果。下面是某一百万次试验中得到的统计结果:
685121
259261
49135
5935
520
28
0
从上到下依次是X=0,1,2……的频数。6个炸弹以上的情况没有出现。
下面是条形统计图,可见,随着炸弹数增加,频数迅速减小。概率最大的事件是没有炸弹。炸弹个数不超过1个的频率高达94%,这和我平时打牌的常识相符合。
基于Docker的自动构建
Wercker现在支持基于Docker的自动部署。我不是很清楚Docker的运作原理。就我现在的理解,Docker是一个虚拟机快照,其中已经配置好了用户所需要的软件。每次运行时,就是解包这个虚拟机然后执行任务。
之前因为ArjenSchwarz/wercker-step-hugo-build这个脚本不支持基于Docker的自动构建,所以我还在使用Wercker的旧的构建模式。
问题在于,在目前基于Docker的构建模式中,默认的虚拟机debian只是一个空壳,像git和wget这样的软件统统都没有安装。
在构建的时候,脚本需要使用wget下载hugo程序。我曾试过在构建之前执行
apt-get -y install wget
但是似乎找不到这个软件包。今天我发现构建脚本更新了,不知道作者是不是也遇到了同样的问题,所以改而使用curl。
我还需要安装git。这个过程会下载很多软件包并安装。构建的时候做一次,部署的时候又做一次,浪费时间和计算资源,我觉得很不合理。
我觉得合理的做法是,在Docker的虚拟机中预先安装好git和hugo,这样每次构建的时候只需解包虚拟机并且运行就可以了,并不需要安装额外的软件包。只是我现在还不知道怎样实现这样的Docker功能。
目前最好的结果是,我找到了yesops/git这个Docker,其中已经安装好了git和curl。这样我就不用再去劳烦apt-get了,应该可以省去不少重复劳动,虽然不是人力劳动而是自动化的机器劳动。
抛硬币问题的另解
周四将要进行《概率论与数理统计》的期末考试。为了表示纪念,研究一个和概率论相关的问题。
继续阅读 →连续抛掷一枚硬币,直到出现连续的两个正面为止。问:抛掷次数的数学期望是多少?
负反馈放大电路
明天将要进行《模拟电子线路》课程的期末考试。今日特地记一道题目以作纪念。
问题是这样的:反馈放大电路如图所示。请
- 判断反馈的组态;
- 估算闭环增益\(A_f\)。
已知:\(R_s\)的值已经很高,可以略去。

高考数学填空题
又是一年高考日。今年江苏省的高考数学卷中,有一道填空题是这样的:
设向量\(\vec{a_k} = \left(\cos{k\pi\over6}, \cos{k\pi\over6} + \sin{k\pi\over6}\right)\),则\[\sum_{k=0}^{11} \vec{a_k}\cdot\vec{a_{k+1}}={?}\]
这样的题似乎只需要你足够地胆大心细总是可以计算出来。
继续阅读 →Hugo的自动化部署
今天根据Hugo网站上的说明,把Hugo的构建和部署工作交给Wercker自动完成。
要把一个Hugo站点发布在GitHub Pages服务上,需要在GitHub创建两个repo:
以前我是按照另一篇说明上的流程操作的,但是命令行的操作并不方便。具体的办法是:在本机运行hugo,生成静态站点。然后把源文件的改动推送到源repo里,再把生成的public目录用Git的submodule或者subtree功能推送到目标repo里边。
使用Wercker自动部署,则工作要轻松许多:当源文件的改动推送到源repo里边以后,Wercker会自动在它的服务器启动构建任务。当master分支成功构建后,就自动地把Hugo生成的静态站点推送到目标repo中。
所以目标repo的事情我就不用管了。如果想要改变部署目标(例如发布到其他的托管主机),只需要修改几条Wercker的设置,非常灵活。
使用自动化部署还给我的编辑流程提供了方便:我现在可以直接在GitHub的web界面上编辑内容。保存以后的更改也会自动地推送到GitHub Page上。另一方面,我可以充分地利用Git的分支功能:如果文章写到一半,可以保存到源repo的draft分支(或者staging分支,看看哪个名字好听而已)里面,而不是保存在本机。这允许我在多个位置进行持续地编辑,才算是有效地体现了GitHub的作用。
Wercker看起来不是很成熟。我读了它的文档,但是看起来十分地简略。最近它推出了一种新的构建模式,使用了Docker的技术。只不过我搞了半天也没有搞定在这种模式下怎么进行自动构建和部署。所以目前仍然运行在旧的模式中。
也有人用的是Travis CI,一个看起来更加成熟的持续集成工具,在GitHub的项目中非常流行。不过Wercker也有它的好处:用户可以创建自己的构建环境(称为box)和脚本(称为step),然后发布出去和其他人共享。我用来构建和部署Hugo的脚本,就是直接拿了别人的来用的,可以说是非常方便,不需要动什么脑筋。鉴于Wercker的解决方案已经足够方便,我现在就先不折腾了。
继续阅读 →计算圆周率至任意精度
下面这段Python 3代码可以产生圆周率π的任意多个有效数字。
def pidigits():
q, r, t, u, i = 1, 180, 60, 168, 2
while True:
y = r // t
yield y
q, r, t, u, i = 10*q*i * (2*i-1), 10*u * (q * (5*i-2) + r - y*t), t*u, u + 54*(i+1), i+1
这是一个永不终止的生成器,每次产生一个十进制的有效数字,依次是3, 1, 4, 1, 5, 9, 2, 6, …
继续阅读 →